
A Summary of ML Application Lessons from Netflix Machine Learning & Recommendations
August 14, 2017
Looking for practical insights and best practices for applied machine learning? It’s hard to do better than the short informative 2014 presentation from Justin Basilico, Research/Engineering Manager for Netflix’s Machine Learning and Recommendations department.
Speaking at the Software Engineering for Machine Learning Workshop (SW4ML) as part of the Neural Information Processing Systems (NIPS) conference, the amount of useful machine learning insight that Basilico manages to pack into 22 minutes is impressive. Any software engineer who is working with machine learning as part of their software development approach has something to learn from Basilico’s experience.
Here are a few simple guidelines learned from the “Lessons Learned from Building Machine Learning Software at Netflix” presentation (video is embedded below):
At a high level, focus on striking a balance
Your team must ensure that their solution is hitting a sweet spot as it fulfills many different—and sometimes conflicting—requirements. In Basilico’s example, the machine learning algorithms must keep recommendations accurate, fresh, diverse, (etc), while the software must work at scale, remain responsive to user actions, maintain enough flexibility to accommodate experimentation, etc.
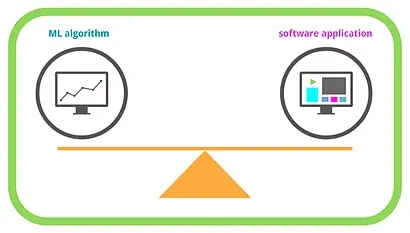
Machine learning (ML) practitioners know that an overly complex model is just as bad as an overly simple one—the key seems to be in establishing parameters of an optimal ML model while balancing those will the parameters for an optimal software application.
Be flexible by allowing computation to happen at various points in the system architecture
Netflix’s ML solution has different parts of computation happening Offline, Nearline, and Online. Basilico points out that while some computational steps like requests processing is done Online, some components can be done anywhere, such as learning, features, or model evaluation.
Think about distribution in terms of layers
IIn terms of training algorithms, Netflix’s machine learning team tackles distribution starting with the easy layers first. They apply models to subsets of the population for independently trained and tuned models. Then, they make models for combinations of hyperparameters, and finally, for each subset of the training data itself. So, while Netflix’s international scale and level of personalization might be much greater than your own undertaking, we can still adopt the general concept of distributing training algorithms in layers, starting with the simplest ones first.
Make experimentation easy
Instead of building a lab software and a production software on two separate engines, Basilico recommends building both on a shared engine, making it easy to experiment no matter the stage of the project. Basilico explains that he often sees ML teams make the mistake of spending a lot of time creating a well-tuned offline model, only to discover that it behaves differently when placed in the production system due to any number of discrepancies (and this means more time spent examining and tweaking).
“The problem, typically, I find bottles down to...having two implementations of the same thing. So it starts off: you have your idea, your experiment code, you build something, you put it into production code. Then, there’s this wall between them, and those things can easily diverge because they’re not kept in sync.”
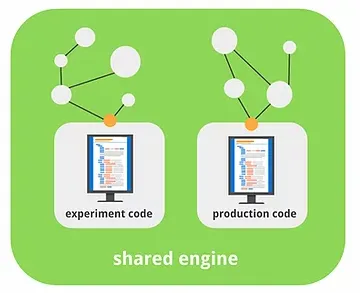
He explains that his team has addressed this problem by using a shared engine where both experiment and production codes can be built upon.
Avoid the limits of "black box" algorithms by ensuring yours are extensible and modular
In mathematical modeling, a "black box" can be useful for getting clear, accurate outputs. In application, however, "black box" algorithms can obscure critical information that might otherwise shed light on why or how something is happening.
Basilico recommends separating algorithms from models, all the while maintaining visibility into the parameters of the models. This will allow you to assemble various models and techniques together for a modular “building block” approach, and it will also provide greater ease in customizing or “tailoring” your algorithms.
Make your models complete by including input and output transformations
When including a machine learned model in an application, you need more than just vector space, representation, and output. To function as part of a complete application, an ML model will need to consider how incoming data (such as user data) will translate into the input needed to run the model, and how the output will translate into actual recommendations. Basilico poses a simple question to help you consider the problem:
“Is this application code, or model code?”
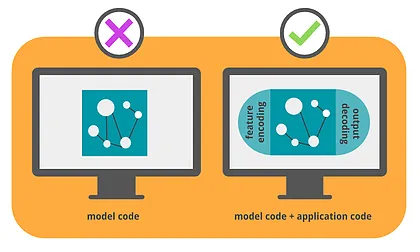
This question is useful for reminding yourself to include feature encoding (input transformation) and output decoding (output transformation) as a critical component of your machine learned model.
Test everything—including your metrics
Don’t fall prey to a sense of false security by believing that the validation cycle inherent to a machine learning model is enough. Basilico points out that while this is tempting, it doesn’t provide very specific or useful information when something’s not working correctly—while the metric might tell you how well the model is (or isn’t) performing, it might not be able to tell you the reason why or where a problem is occurring, for example. Separately test your metrics, test each component (data, idea, code, etc.), and test the system as a whole.
“Lessons Learned from Building Machine Learning Software at Netflix” presentation video:
Or, find a link to watch the full presentation here.
Our Recent Posts
April 24, 2018
March 2, 2018
February 28, 2018
Archive
©2010 - 2018 by Tribal Interactive Inc.

